


If you stare at something for a little bit of time and let your mind wander, you can think of a new way to analyze something that you have looked at a bunch of times. We squinted at the June 2024 Top500 supercomputer rankings, which are out a month earlier because renting the facility for the ISC24 event in Hamburg is much less expensive in May than it is in June, and came up with a new way to talk about it.
In this story, we are going to talk about only the new machines on the list, big and small.
And not surprisingly, Nvidia’s combination of its “Grace” CG100 Arm server processor and “Hopper” GH100 GPU accelerator was a big hit among all of the new machines that were booted up in time to run the High Performance LINPACK benchmark before the cutoff for the June list.
There are 49 such machines on the June 2024 list, and they employ a variety of CPUs, GPUs, and interconnects to deliver varying levels of performance and concurrency. Here is a summary table that breaks them down by type of machine and provides the salient performance specs for each system:
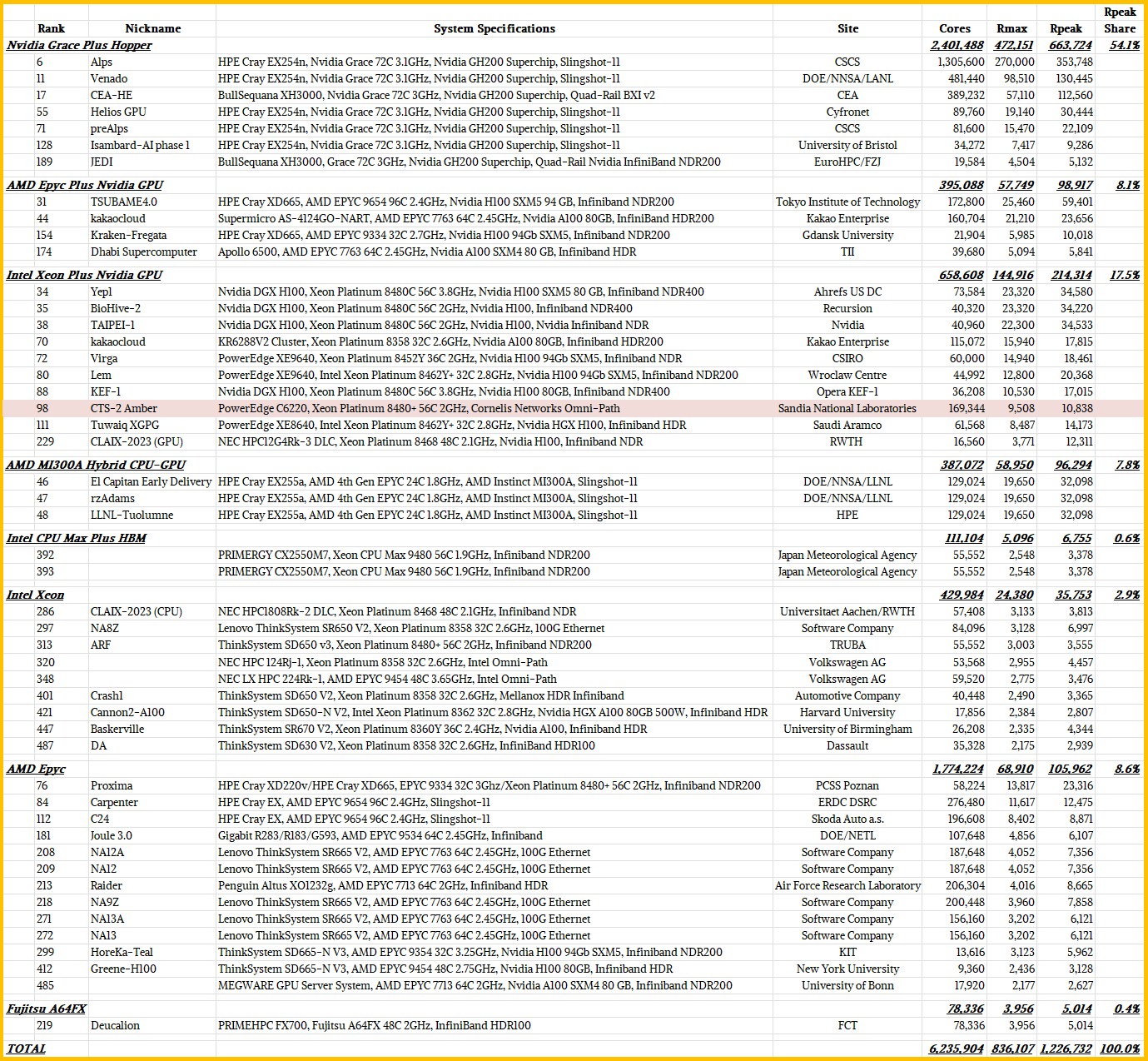
Unless your eyes are a lot better than ours, and your screen is enormous, you will have to click to enlarge that image.
Across those 49 machines, there are nearly 6.24 million cores of concurrency in the aggregate, which is comprised of the cores in the CPUs plus the streaming multiprocessors in the GPUs – or their analogs in hybrid architectures like the Fujitsu A64FX processor that is at the heart of the “Fugaku” supercomputer at RIKEN Lab in Japan and that is used in the new “Deucalion” system installed at FCT in Portugal. The entire Top500 list for June had 114.65 million cores, so these 9.8 percent of the Top500 machines represented only 5.4 percent of the cores.
If you add up the peak theoretical throughput of the compute engines in these 49 machines, it is 1.23 exaflops, which is about a tenth of the 9.8 percent of the exaflops embodied in the entire Top500 list for June 2024, which was 12.5 exaflops. But if you look at the Rmax ratings in teraflops for these machines as a group, they account for 836.1 petaflops, or 10.2 percent of the 8.21 exaflops of Rmax on the entire Top500 list.
Here is where it gets interesting. Thanks to the “Alps” system at CSCS in Switzerland, which is the first Grace-Hopper supercomputer installed and at the moment the most powerful as well, with an Rpeak of 353.75 petaflops across more than 1.3 million cores and SMs, the seven Grace-Hopper machines have 54.1 percent of the composite Rpeak of all of the new machines.
Interestingly, the Jedi system installed at Forschungszentrum Jülich in Germany, which a fairly small Grace-Hopper system, is ranked number 189 on the Top500 but is ranked number one at 72.73 gigaflops per watt on the HPL benchmark. The phase one of the Isambard-AI system at the University of Bristol in England, which is ranked number 128 on the Top500, is also a Grace-Hopper machine and that delivers 68.84 gigaflops per watt on the Green500 list. And the new number three on the Green500 is the new “Helios” Grace-Hopper system at Cyfronet in Poland, which is ranked number 55 on the Top500, comes in at 66.95 gigaflops per watt.
The “Frontier” system at Oak Ridge National Laboratories, which is still the fastest machine in the world, is rated at 1.71 exaflops peak but 1.21 exaflops sustained on HPL, delivers 52.93 gigaflops per watt, and the number two machine on HPL, which is the “Aurora” system at Argonne National Laboratory, is rated at 1.98 exaflops Rpeak but only 1.01 exaflops Rmax on HPL, delivering only 26.15 gigaflops per watt. The “Summit” pre-exascale supercomputer built from Power9 processors and Nvidia “Volta” V100 GPUs, delivered 14.72 gigaflops per watt on HPL for its Green500 ranking, only slightly behind the 15.42 gigaflops per watt for the Fugaku system at RIKEN.
Of the new machines on the June 2024 Top500, fourteen of them are based on Nvidia GPUs – mostly H100s but sometimes their predecessor “Ampere” A100s – using either AMD Epyc processors or Intel Xeon processors as hosts. All of these fourteen machines using X86 CPUs and Nvidia GPUs have InfiniBand interconnects except for the “Amber” CTS-2 system at Sandia National Laboratory, which uses a 100 Gb/sec Omni-Path interconnect from Cornelis Networks.
Interestingly, there are three identical machines based on AMD’s Instinct MI300A hybrid CPU-GPU compute engines installed at Lawrence Livermore National Laboratory, which made it into the Top50 and which are showing only 61.2 percent computational efficiency as testbeds for the future “El Capitan” system that will almost certainly be ranked number one on the November 2024 Top500 list. We are guessing it will come in at around 2.3 exaflops peak and about 1.5 exaflops Rmax on the HPL test, but the efficiency could be higher and push that up to maybe 1.6 exaflops to even 1.7 exaflops, which would represent 65 percent to 74 percent computational efficiency.
By the way, those two Fujitsu Primergy clusters based on Intel’s HBM variant of the “Sapphire Rapids” Xeon 5 processors come in with a 75.4 percent computational efficiency, which would seem to argue for HBM memory on CPUs. And that Deucalion machine at FCT in Portugal is delivering 79 percent computational efficiency on HPL.
The computational efficiency of the all-CPU machines among the 49 new systems added to the June 2024 Top500 are all over the place, from a low of 44.7 percent to a high of 93.1 percent. The average is around 68.5 percent.